Apache Beam
Overview

-
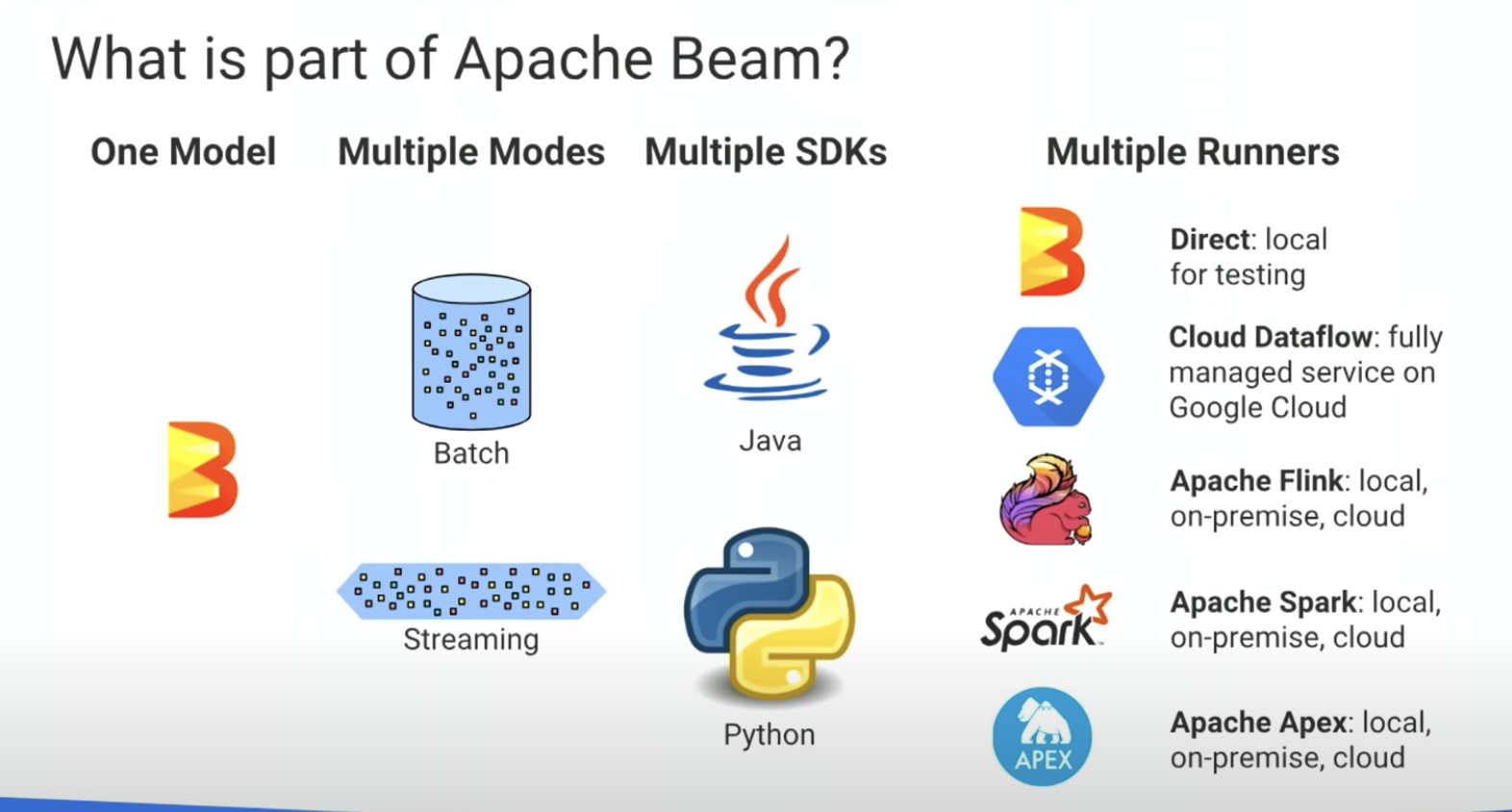
Beam is a collection of SDKs for streaming processing pipeline
-
name come from 'Batch' + 'strEAM'
-
-
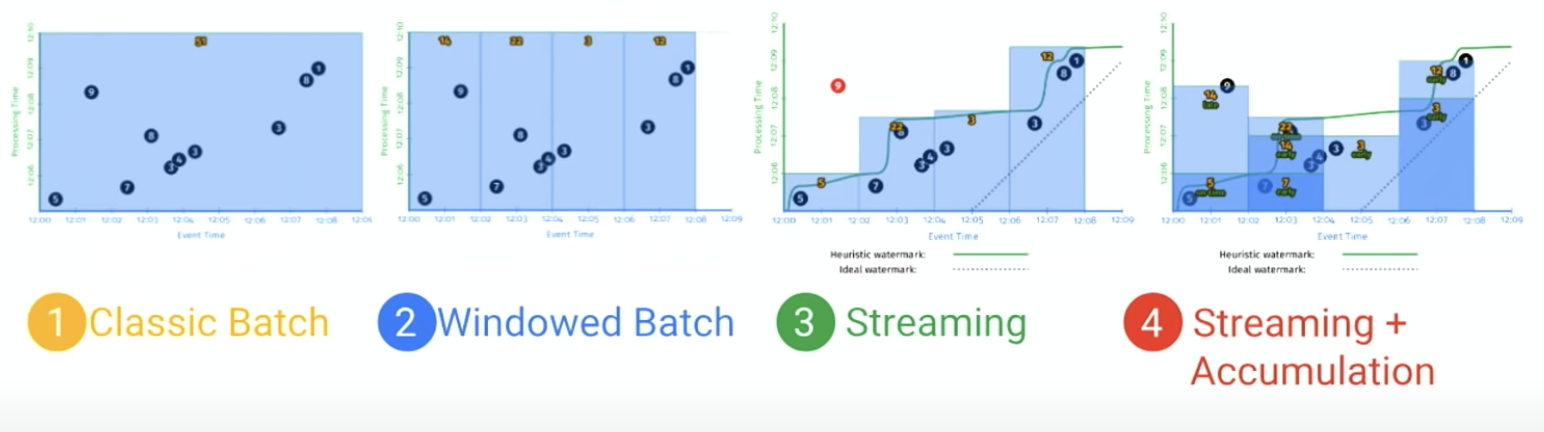
- Streaming + accumulation: built-in fucntionality for handle late packets
-
Beam Pipeline is a DAG graph
-
Bounded (batch) vs Unbounded (streaming, with windows)
-
PCollection == data elements
- iterable collection
- immutable -readonly
-
PTransform == nodes in the graph
records = (p | 'Read from PubSub' >> beam.io.ReadStringsFromPubSub(topic=..., id_label='MESSAGE_ID') | 'Parse JSON to dict' >> beam.Map(lambda e: json.load(e)) # branch 1 records | beam.ParDo(AddTimstampToDict()) | beam.WindowInto(window.SlidingWindows(..)) | beam.ParDo(AddKeyToDict()) | beam.GroupByKey() | beam.Pardo(CountAverages()) | beam.io.WriteToBigQuery(...) # branch 2 records | beam.io.WriteToBigQuery(...)
-
-
Cloud Dataflow - managed service
On AWS
- Workshop on using Beam with Kinesis Flink: https://beam-streaming-analytics.workshop.aws/en/beam-on-kda.html