Ch03 - Storage and Retrieval
Chapter 3: Storage and retrieval
Data structures that power your DB
Hash indexes
-
Use log for writing key + value; key + value
-
Index: Key -> byte offsets mapping
-
Used by - Bitcask - default storage engine for Riak - hashmap stored in memory
-
Good for: value of each key is updated frequently
-
Log compaction:
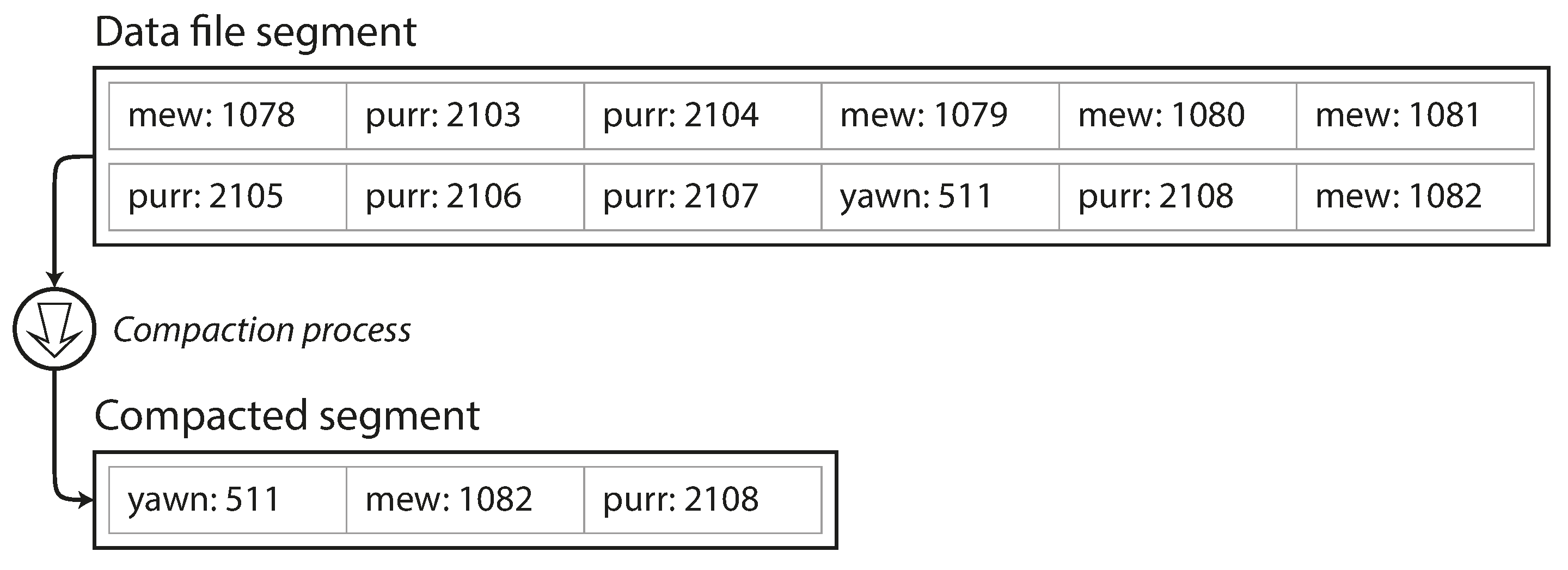
- Segment log files
- Keep only the most recent update for each key
- Merging and compaction is written to a new file - in background

- After compaction, switch to new merged segment
-
Lookup: each segment has its own hash table. First check most recent segment for key, then prior, …
-
File format: binary format is more space efficient and faster than CSVs
-
Deleting records: write tombstone record. During merge, discard prev entries
-
Crash recovery: If the database is restarted, the in-memory hash maps are lost. Snapshot segment hashmap on disk to speed up recovery
-
Concurrency control: one writer thread. Because of immutability, reads can be concurrent
-
Limitations:
- Table must fit in memory. Not good for large number of keys. Hashmap on disk bad perf: lots of random IO
- Range queries not efficient
SSTables and LSM trees
- SSTables introduced by Google bigtable paper
- Sorted String table
- each key only appears once within each merged segment
- Efficient merging
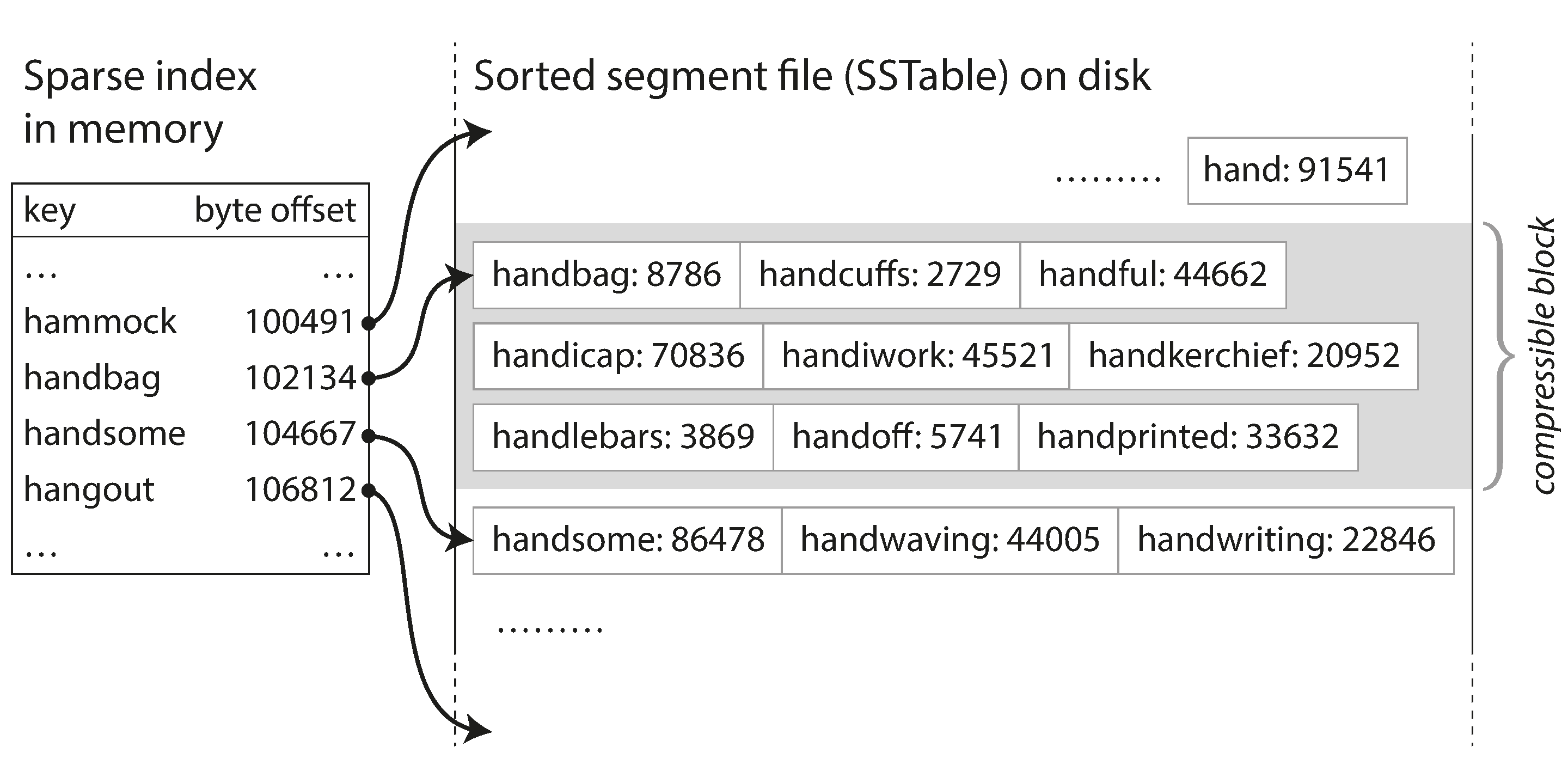
- When write comes in - use in-memory balanced tree (i.e. memtable)
- After size too big: write to disk as SSTable file
- When read: first search in memtable, then in most recent on-disk segment, etc.
- Run merge and compaction in background
- Problem: crashes - most recent write is lost <-- keep a separate log for each write immediately on disk
- Make LSM tree (log-structured merge-tree) out of SSTables
- keeping a cascade of SSTables that are merged in the background
- LSM storage engines: based on this principle of merging and compacting sorted files
- Performance optimizations: bad perf if key does not exist -- use a bloom filter
B-tree
- Compared to log structed indexes : MB sized segments; B tree breaks 4KB blocks/pages. corresponds more closely to the underlying hardware.
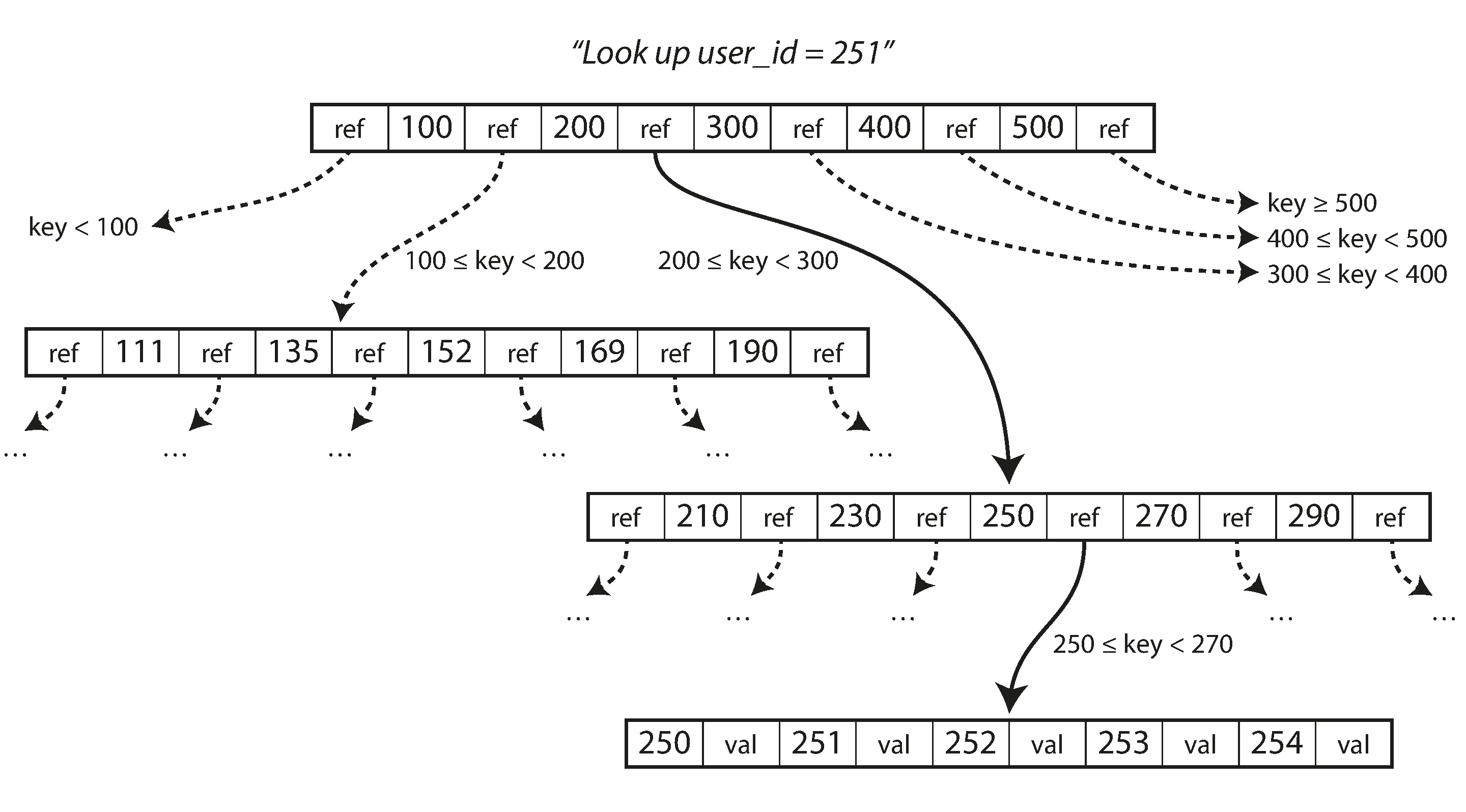
- Most databases can fit into a B-tree that is three or four levels
- Grow a B tree by splitting a page
- to make the database resilient to crashes: WAL - write-ahead log or redo log
- Concurrency: protect with latches
- Optimizations:
- Use copy-on-write instead of WAL
- Abbreviating keys
- Try to keep leaf pages sequential - harder than LSM trees
- Additional pointers - such as sibling pages
Comparing B trees and LSM trees
- LSM-trees are typically faster for writes, whereas B-trees are thought to be faster for reads - however no conclusive benchmark
- Pro of LSM trees:
- A B-tree index must write every piece of data at least twice & write an entire page at a time - write amplication
- LSM-trees are typically able to sustain higher write throughput than B- trees, partly because they sometimes have lower write amplification
- LSM-trees can be compressed better - B-tree storage engines leave some disk space unused
- Con of LSM
- compaction process can sometimes interfere with the performance of ongoing RWs - impact higher percentiles-
- If ill-configured, compaction cannot keep up with the rate of incoming writes - unmerged segments on disk keeps growing until you run out of disk space, and reads also slow down because they need to check more segment files
- B tree each key exists in exactly one place - easier for locks & transaction semantics
- B tree common in relational, LSM in newer DBs
Other strcutures
- Storing values within index:
- row is stored elsewhere (ie heapfile)
- clustered index - row with index
- In MySQL innDB - primary key is clusterd, secondary index refer to the primary key
- Compromise: include some columns - covering index
- Multi-column indexes
- Concatenated index
- Multi-dimensional index for spatial data
- Option 1: translate 2 dimensional location into a single number using a space filling curve
- Option 2: R trees with PostgreSQL’s Generalized Search Tree
- Full-text search and fuzzy indexes
- In memory DB:
- performance advantage of in-memory databases is not due to the fact that they don’t need to read from disk.
- But because they can avoid the overheads of encoding in-memory data structures in a form that can be written to disk
- Also offer data models difficult to implement with disk based indexes e.g. Redis
- Future: NVM (non-volatile memory)