Inference accelerator
GPUs vs AWS Inferentia vs Amazon EIs
Deep learning inference acceleration landscape
- CPUs acquired support for advanced vector extensions (AVX-512)
- GPUs acquired new capabilities such as support for reduced precision arithmetic (FP16 and INT8) further accelerating inference
- AWS Inferentia, a custom-designed ASIC
Considerations
-
Model type and programmability: model size, custom operators, supported frameworks
- AWS Inferentia - fixed set of supported operations exposed via AWS Neuron SDK compiler
- CPU - fully programmable
- GPU - in between
- if have custom code written in high level languages, fall back to CPU:
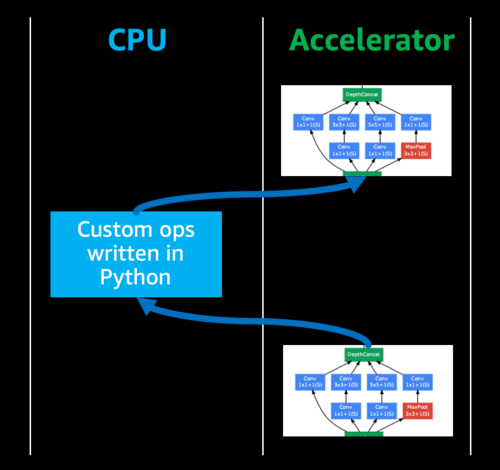
- NVIDIA GPUs: option to reimplement custom code using CUDA.
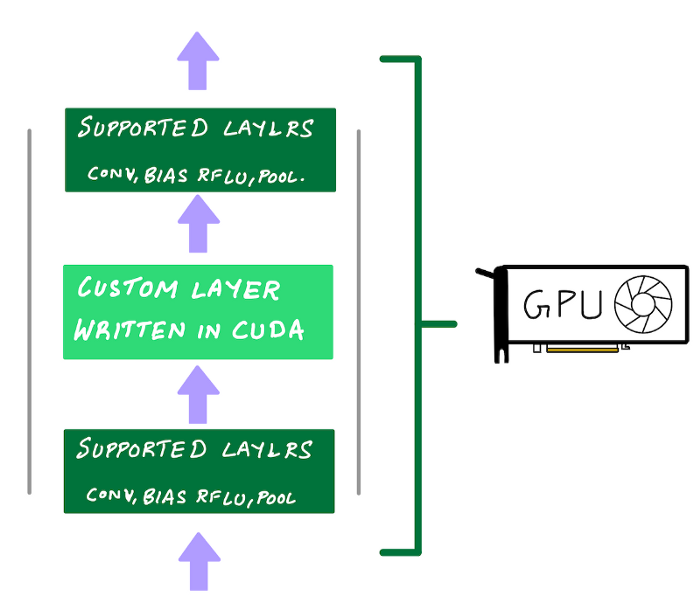
- this is hard to do w ASIC
- NVIDIA GPUs: option to reimplement custom code using CUDA.
-
Target throughput, latency and cost:
-
GPUs are throughput processors
- If latency is not critical, GPU utilization can be kept high and cost low - great for batch processing & offline inference
- if you are unable to keep your GPU utilization at its maximum at all times, due to e.g. sporadic inference request, cost / inference request goes up
- better to use Amazon Elastic Inference which lets you access just enough GPU acceleration for lower cost.
-
CPUs are not parallel, but may be better for realtime inference of smaller models as long as latency is acceptable
-
Inferentia’s performance and lower cost could be most cost effective and performant option if model is fully supported
-
-
Compiler and runtime toolchain and ease of use
- GPU:
- deep learning framework is good but not optimized
- use a dedicated inference compiler such as NVIDIA TensorRT for up to 10x speedup
- Quantization: reduce precision - from FP32 -> FR16 or INT8
- Graph fusion: fusing multiple layers/ops into a single function call
- GPU:
AWS Inferentia
- precisions:
- automatically cast your FP32 model to BF16
- or can provide model in FP16
- increase performance by:
- batching: reducing cost of loading weights for each layer from external memory for each input
- pipelining: load weights of different subgraphs on different NeuronCores
- both require setting options during compilation
- Using all NeuronCores on your Inf1 instances:
- smallest instance type: inf1.xlarge automatically perform data parallel execution on all 4 NeuronCores (=replicating your model 4 times and loading it into each NeuronCore and running 4 Python threads to feed input to data to each core)
- larger instance: must spawn multiple threads and use python threadpools
- divide NeuronCores to run different models
Amazon Elastic Inference
Attached through the network using an AWS PrivateLink
Why choose Amazon EI over dedicated GPU instances?
- if don’t have sufficient demand or multiple models to serve and share the GPU to keep up utilization, can attach "just enough" GPU acceleration to a CPU instance
- The cost of the CPU instance + EI accelerator would still be cheaper than a dedicated GPU instance
- EI adds some latency compared to GPU instance, but can be faster than CPU only
- need to use an EI enabled framework such as TensorFlow, PyTorch or Apache MXNet
Choosing the right GPU for deep learning on AWS
- G4 instance: NVIDIA T4 GPUs
- go-to for inference
- FP64, FP32, FP16, Tensor Cores (mixed-precision), and INT8 precision types
- 16 GB of GPU memory
- P3: if need more throughput or need more memory per GPU